Solving the Shove/fold Game with TensorFlow
Google recently open-sourced TensorFlow (website, whitepaper), a software package primarily meant for training neural networks. However, neural nets come in all shapes and sizes, so TF is fairly general. Essentially, you can write down some expression in terms of vectors, matrices, and other tensors, and then tell TF to minimize it.
I ran through a couple of their very well written tutorials and then decided to try it out on one of my standard toy problems: the HUNL shove/fold game.
As a reminder, shove/fold is a 2-player no limit hold’em model game where play proceeds as follows:
- Both players start with stacks of
S. - The player in the BB posts blind, and the player in the SB posts blind.
- The SB can go all-in or fold.
- Facing an all-in, the BB can call or fold.
Notice that the SB’s strategy is completely specified by his shoving range, and the BB’s by his calling range. The equilibrium for this game is well known and exhaustively described in
EHUNL v1
chapter 3.
So, the equilibrium is a pair of strategies, one for each player, where both are maximally exploiting each other, simultaneously. There are several ways we can find it. In the Solving Poker video series, we used the Fictitious Play algorithm. There, we maintained guesses for both players’ optimal strategies and repeatedly calculated each player’s maximally exploitative counter strategy, taking a small step towards it each time.
An alternate approach lets express the problem directly as an optimization problem, which is what TF is good at. The BB’s equilibrium strategy is the one that minimizes the EV of the SB’s maximally exploitative (ME) response. So, we just need to write down the EV of the SB’s ME strategy as a function of the BB’s strategy and then minimize it.
Let’s get started. Feel free to follow along in a Jupyter (née iPython) notebook after installing TF.
First, import some libraries.
import tensorflow as tf
import numpySecond, we’re going to need some data. There are distinct starting hands in NLHE, so we can describe a player’s range with a vector of numbers. To do this, we need to determine some sort of ordering of all the hand combos. I’ll give some code to convert from a vector to a human-understandable picture of a range and the end of this article. For now, the particular order doesn’t matter as long as we’re consistent.
We’ll need hand-vs-hand equities, and we can put the equity of every starting hand versus every other in a matrix. The file pf_eqs.dat contains such a matrix as output by numpy.savetxt. Of course, some entries in that matrix don’t make sense. If two starting hands have a card in common, they can’t both be held simultaneously. The file pf_confl.dat holds another matrix where every entry is either 0 or 1. A 1 indicates that we can compare two hands, and a 0 indicates that the hands conflict.
pfeqs = numpy.loadtxt("pf_eqs.dat")
pfconfl = numpy.loadtxt("pf_confl.dat")Now we’ll use TensorFlow to set up and minimize the SB’s maximally exploitative EV (MEEV) as a function of the BB’s strategy. The process will be:
- Define some constants: the two arrays we just loaded and the stack size.
- Define a variable: the BB’s calling range.
- Write the SB’s MEEV in terms of those things.
- Use TF to find the value of the variable (BB’s calling range) that minimizes the SB’s MEEV.
First, the constants. The tf.constant method creates a TensorFlow constant. We give it the data, the type of the data, the shape of the data, and a name that TF will give back to us in error messages if we mess up. We’ll choose a stack size of here for no particular reason.
equity_array = tf.constant(pfeqs, tf.float32, [1326, 1326], name='equity_array')
confl_hands = tf.constant(pfconfl, tf.float32, [1326, 1326], name='confl_hands')
S = tf.constant(10, tf.float32, [], name='S')The variable which will be represented by an instance of the tf.Variable class. We pass in an initial value: a vector of zeroes.
_bb_call_range = tf.Variable(tf.zeros([1326,1]))Now, the vector representing the BB’s calling range should have numbers, where each number corresponds to a particular hand and represents the probability he will call an all-in with that hand. Since it’s a probability, it should be a number from to . But the optimizer isn’t going to know about that constraint. Instead, it will change the entries of this vector in any way necessary to minimize the MEEV. We need to account for this, or else the result will probably tell the BB to call with aces 1000000000% of the time and fold everything else ;).
So, I use a trick here and define bb_call_range to be the sigmoid function of _bb_call_range. From the graph of the sigmoid function, we can see that this function takes any real number as input and produces something between and as output. This way, we can let the optimizer do whatever it wants to _bb_call_range, and by doing so, it will be able to make the entries of bb_call_range anything and only anything between and .
bb_call_range = tf.sigmoid(_bb_call_range)Of course, the sigmoid function isn’t the only one that would work here. I’d be interested if anyone has a sufficiently different way to introduce bounded variables. I suspect something involving subclassing either Variable or the optimizer op is possible…
Now for some math. Big picture, we want the SB’s MEEV, which is the average of his MEEV for every particular hand, which is the maximum of his EV of folding and his EV of shoving with that hand. We’ll start with something easy: the EV of folding each hand. If he open-folds, the SB ends up with a stack of , regardless of his holding.
sb_ev_fold = (S-0.5)*tf.ones([1326,1])Now for the EV of jamming. We start by finding the number of hand combos in the BB’s range for each SB hand. This is almost just a sum of all the entries in bb_call_range, except that we need to remove the entries that correspond to hands that conflict with the SB’s hand because of card removal effects. We achieve this by multiplying with the confl_hands binary array.
bb_num_calling_hands = tf.matmul(confl_hands, bb_call_range)The number of BB hand combos left after we fix a particular SB hand is , so we divide bb_num_calling_hands by to get the chance the BB calls a shove.
chance_bb_calls = bb_num_calling_hands / 1225The SB’s equity when called with each particular hand is just the average of his equity versus each possible BB holding, weighted by how likely the BB is to hold each holding after calling an all-in.
sb_equity_when_called = (tf.matmul(equity_array, bb_call_range)) / bb_num_calling_handsAnd then the SB’s EV of shoving is the average of his stack size when the BB does and does not call, weighted by the probability of each case.
sb_ev_shove = sb_equity_when_called * (chance_bb_calls)*(2*S) + (1.0-chance_bb_calls)*(S+1.0)Keep in mind that sb_ev_shove here is a vector of length – we have a (potentially) different EV for each SB holding. TensorFlow makes this easy in that basic operations (*, +) between objects of the same shape are done elementwise, and operations between a matrix or vector and a number (such as ) are handled via broadcasting.
Finally, we can write the SB’s MEEV with each hand and take the average to get his average MEEV.
sb_meev_by_hand = tf.maximum(sb_ev_shove, sb_ev_fold)
sb_meev = tf.reduce_sum(sb_meev_by_hand) / 1326Now for the optimization. Up to this point, we haven’t actually done any calculations. We’ve simply set up the sequence of operations that lead from our constants and the variable describing the BB’s range to the SB’s MEEV. Actually, this sequence forms a graph, and it’s possible to directly visualize this graph. Do you see the inputs at the bottom and the output up top? Which part of this graph corresponds to the EV of folding calculation and which to the EV of shoving?
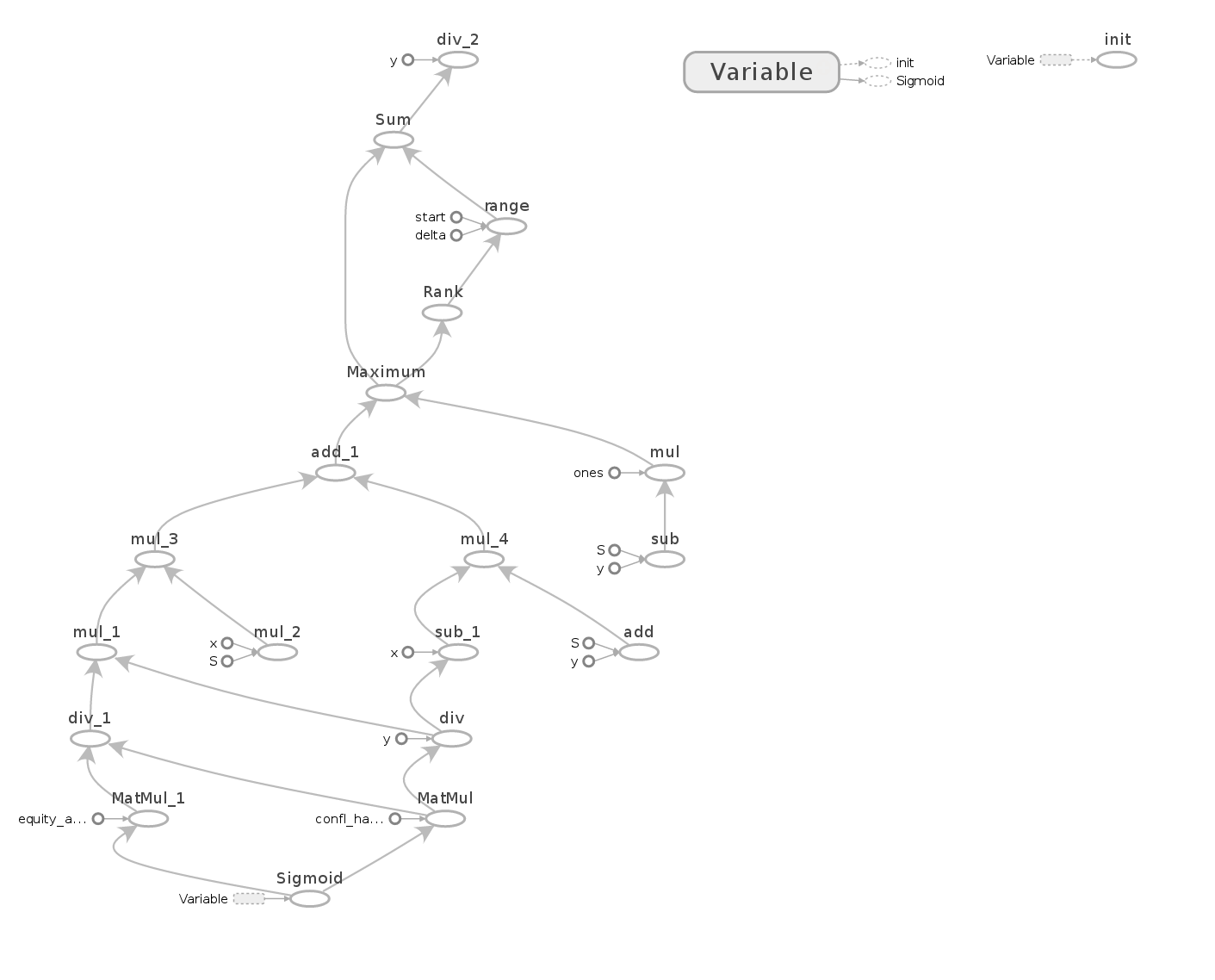
We’ll now define an Optimizer whose minimize method annotates this graph with various bits of info (about how to compute and apply gradients) necessary to do the actual optimization. We’ll use a GradientDescentOptimizer and give it the quantity we want to minimize (sb_meev) and the list of variables we want to optimize ([_bb_call_range]).
bb_train_step = tf.train.GradientDescentOptimizer(1000.).minimize(sb_meev, var_list=[_bb_call_range])Finally, we need to run the optimization. We’ll set up a tf.Session object which is responsible for tracking the state of our optimization. We initialize all our variables, and then we run the optimizer a bunch of times. Finally, we extract the BB’s optimal strategy.
sess = tf.Session()
sess.run(tf.initialize_all_variables())
for n in range(10000):
sess.run(bb_train_step)
bb_range = sess.run(bb_call_range)Lastly, as promised, here’s some code to create a nicely-formatted version of the BB’s range, presented without comment. It creates an SVG, and the _repr_svg_ magic will cause the image to be embedded directly if your browser if you’re using Jupyter. Otherwise, save the text and open it in your browser or some such.
class RangeDrawer:
def __init__(self, r):
self.r = r
def _repr_svg_(self):
ranks=['2','3','4','5','6','7','8','9','T','J','Q','K','A']
suits=['c','s','d','h']
weights={}
counts={}
c = 0
for r1 in range(len(ranks)):
for r2 in range(r1, len(ranks)):
for s1 in range(len(suits)):
for s2 in range(len(suits)):
if r1 == r2 and s1 >= s2:
continue
if s1 == s2:
hand = ranks[r2]+ranks[r1]+'s'
else:
hand = ranks[r2]+ranks[r1]+'o'
weights[hand] = weights.get(hand, 0) + self.r[c]
counts[hand] = counts.get(hand, 0) + 1
c += 1
result = '<svg xmlns="http://www.w3.org/2000/svg" version="1.1" width="325" height="325">'
for i in range(len(ranks)):
for j in range(len(ranks)):
if i<j:
hand = ranks[j]+ranks[i]+'s'
else:
hand = ranks[i]+ranks[j]+'o'
frac = weights[hand] / counts[hand]
hexcolor = '#%02x%02x%02x' % (255*(1-frac), 255, 255*(1-frac))
result += '<rect x="' + str((len(ranks)-i)*25) + '" y="' + str((len(ranks)-j)*25) \
+ '" width="25" height="25" fill="'+hexcolor+'"></rect>'
result += '<text x="' + str((len(ranks)-i)*25)+'" y="'+str(((len(ranks)-j)+1)*25-10) \
+ '" font-size="11" >' + hand + '</text>'
result += '</svg>'
return result
RangeDrawer(bb_range)BB calling range:

Questions:
- What does the graph look like after we create the Optimizer?
- Try other types of Optimizers and/or a different learning rate. Can you train faster?
- Find the SB’s optimal shoving range. You need to express the BB’s ME EV in terms of the SB’s strategy and minimize that to find the SB’s jamming range. Make sure to write the BB’s EV at the beginning of the hand and not after he is facing a shove.